Trading platforms rarely fail because the front end looks wrong. They fail because the machinery underneath is slow, brittle, expensive, or impossible to evolve safely.
In buy-side & sell-side trading, that problem is amplified by latency requirements, operational risk, and the reality that a meaningful share of firms still rely on private infrastructure for critical workloads rather than placing everything in the public cloud.
That reality is not a historical artifact. Coalition Greenwich reported in May 2026 that 53% of firms still leverage private infrastructure on premise for trading technology workloads, even amid the continued growth of cloud adoption. The reason is straightforward: for trading systems, infrastructure choices are still driven by cost, latency, and control.
This article explains the problem that emerged inside a modern trading-platform business, the engineering fabric built to solve it, and why the same approach can help other trading desks and vendors that are carrying too much operational drag.
The Problem: Too Much Complexity for Too Little Leverage
As trading platforms mature, engineering organizations often accumulate the same pathologies.
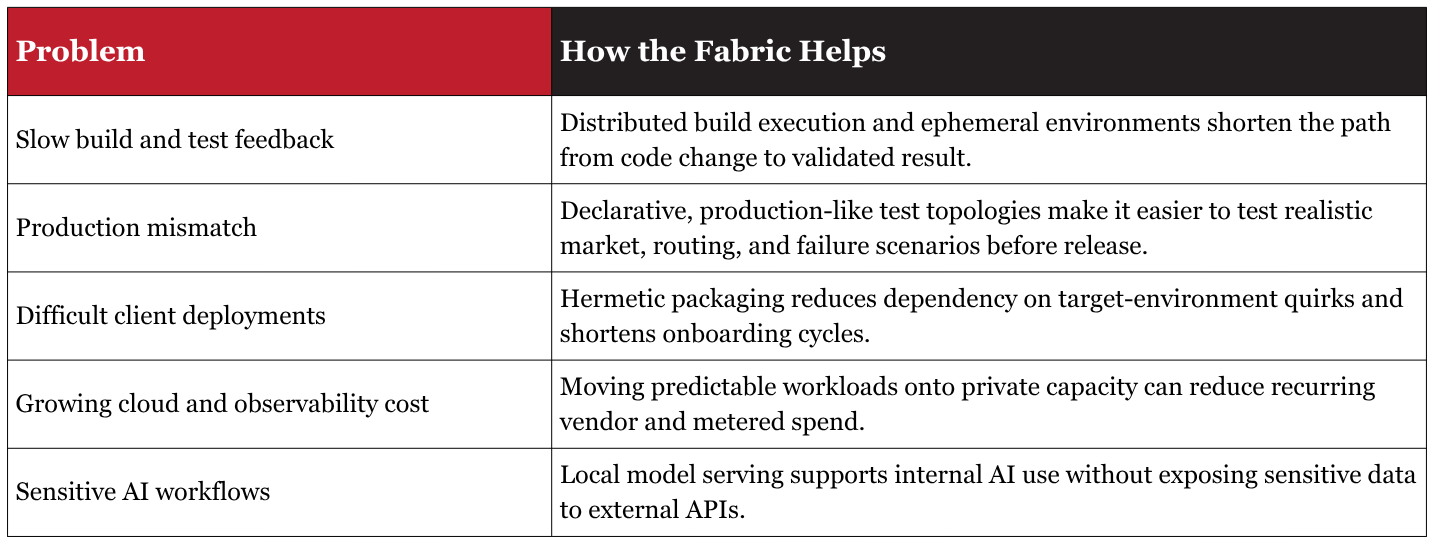
- Build pipelines slow down as codebases and service counts grow.
- Integration testing becomes painful enough that teams reduce how often they run realistic full-system scenarios.
- Deployments into locked-down or legacy client environments turn into bespoke projects.
- Observability, cloud, and infrastructure tooling bills rise faster than the underlying business value they create.
That last point matters more than many teams admit. Honeycomb has argued that a typical observability stack often lands in the range of 20% to 30% of infrastructure spend, with the exact number depending on requirements, customer expectations, and team setup. Even when the tools are useful, that spend compounds with cloud egress, managed services, and the engineering headcount required to operate increasingly fragmented environments.
For a complex, distributed trading platform, the cost is not just financial. The hidden cost is slower iteration. When realistic test runs take too long, teams either wait or cut corners. When environments drift from production, confidence drops. And when deployment targets vary wildly, onboarding and upgrades become long, expensive exercises in exception handling.
The result is familiar to many buy-side desks and vendors: more vendors, more cloud services, more handoffs, and less real leverage.
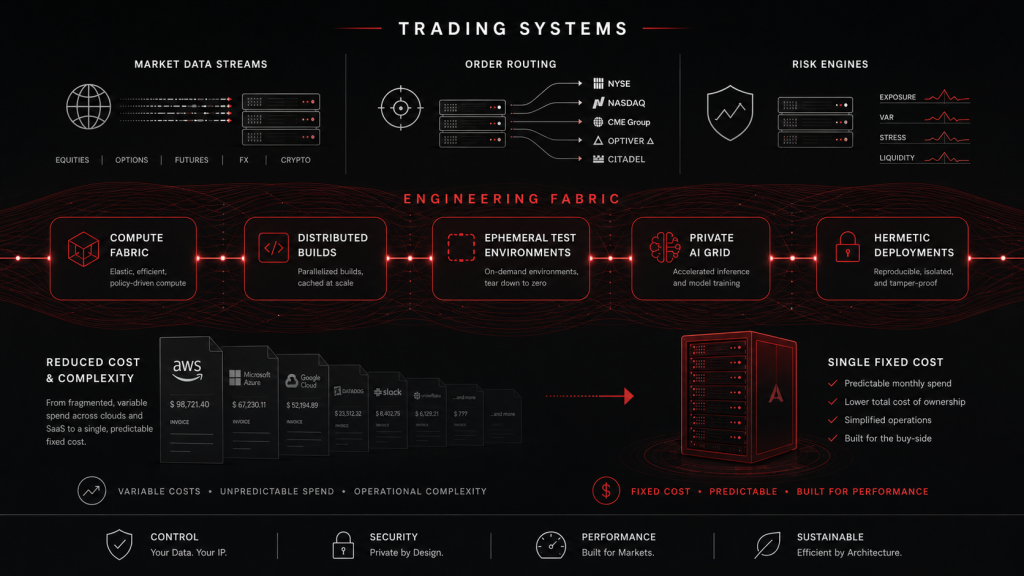
The Solution: A High-Leverage Engineering Fabric
The response was not to add another layer of tooling. It was to replace fragmented operational overhead with an integrated engineering fabric designed around the actual needs of a high-performance trading platform.
At a high level, the fabric combines five capabilities into one operating model:
- Private compute fabric for builds, tests, simulation, and internal services.
- Distributed compilation matrix for large, parallelized native-code builds.
- Ephemeral integration tester that boots full multi-service environments on demand.
- Private AI grid for internal engineering workflows without public API dependency.
- Hermetic deployment engine that targets conservative Linux baselines and minimizes environmental friction.
This is not private infrastructure for its own sake. It is an engineering system built to improve throughput, reduce risk, and keep operating costs predictable in a domain where production realism matters.
What That Looks Like in Practice
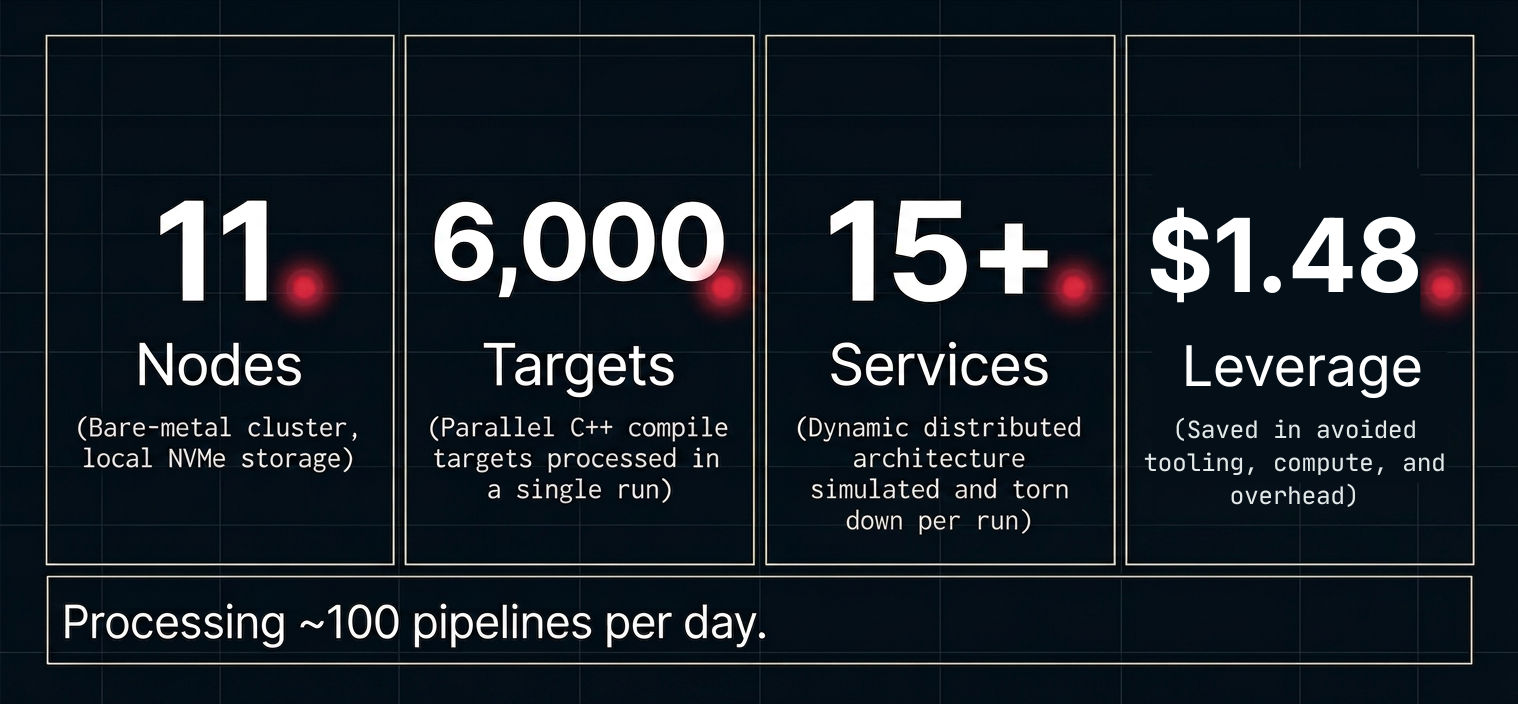
The fabric described here runs on an 11-node bare-metal cluster using fast local NVMe storage and dual-pool storage orchestration. It supports around 100 pipelines per day and processes up to 6,000 parallelized C++ compile targets in a single run. Its core integration pipeline dynamically boots a distributed architecture of more than 15 services, injects large custom configurations, simulates production trading scenarios, and tears the environment down after execution.
Operationally, that compresses a local 8-hour integration run into roughly 30 minutes, and that pipeline can be executed up to 30 times a day. For internal engineering workflows, a private AI grid serves large models locally through a custom router, avoiding external per-token dependency for sensitive use cases. Deployment is handled through self-contained artifacts engineered to run against a legacy-friendly Linux baseline, making it possible to drop a tarball, execute a script, and stand up services without a long dependency negotiation.
Taken together, those choices create a meaningful structural difference in cost and speed. Internal modeling of equivalent throughput using public cloud compute, enterprise SaaS, and the additional operating headcount required to manage those systems indicated roughly $1.48 million per year in structural leverage. That figure reflects avoided tooling, compute, and operational overhead rather than a single line-item saving.
Why the Numbers Matter
A savings number by itself is not the story. The more important point is what those savings buy.
First, they buy engineering speed. If realistic, full-stack testing can run in 30 minutes rather than most of a workday, developers can validate more change safely. That shifts teams away from big-bang releases and toward smaller, more controlled iterations. In a trading context, where infrastructure failures can damage client confidence and market responsiveness, that matters.
Second, they buy deployment portability. Many trading systems still have to live inside conservative infrastructure estates. Greenwich’s 2026 research reinforces the point that private infrastructure remains prevalent because firms still care deeply about latency, cost control, and operational certainty. A hermetic deployment model reduces the friction of supporting those environments.
Third, they buy cost predictability. Metered infrastructure is powerful, but it also encourages cost creep when builds, telemetry, simulations, and internal AI usage all expand at once. The combination of fixed private capacity and targeted external services can be economically cleaner than pushing every workload through public cloud pricing models.
What Problems This Solves for Trading Desks and Vendors
For other trading desks and software vendors, the appeal of this model is not ideological. It is operational.
This is especially relevant for organizations with multi-service trading or risk stacks, large native-code codebases, or client deployments into tightly controlled infrastructure. It also aligns with the broader shift toward platform engineering as a business capability rather than an abstract infrastructure exercise. Platform Engineering notes that enterprise buyers increasingly want service providers to map platform work to business outcomes and adapt it to real organizational contexts rather than simply installing more tools.
Why This Matters Now
The market is moving in two directions at once. On one hand, cloud adoption continues to expand. On the other, high-performance trading workloads still frequently remain in private or hybrid environments because their economics and operational constraints are different. Exegy’s 2026 overview of trading infrastructure describes the stack as the engine that ingests market data, processes signals, manages risk, routes orders, and executes while preserving performance, resilience, and operational control.
That description is a reminder that infrastructure is not back-office plumbing in trading. It is part of the product.
For trading desks, inefficient engineering infrastructure slows adaptation. For vendors, it increases implementation cost and makes support harder to scale. In both cases, teams end up funding complexity rather than capability.
A Practical Way Forward
The point is not that every trading desk should copy a specific 11-node cluster design. The point is that many firms can materially improve their economics and delivery model by adopting the same principles:
- Put predictable, high-throughput workloads on infrastructure built for them.
- Treat integration environments as disposable and reproducible, not precious shared assets.
- Package software so that deployment friction stops dominating client onboarding.
- Keep sensitive internal AI workflows close to the systems and data they support.
- Measure platform investments by business outcomes: release speed, implementation effort, operational risk, and total cost.
For organizations dealing with rising infrastructure spend, fragile test pipelines, or difficult deployment environments, that change can be substantial.
Where the Fabric Can Help Others
There is a natural extension of this approach beyond internal use. Trading desks and vendors facing similar constraints can benefit from a tailored version of the same engineering fabric: discovery of current bottlenecks, design of a private or hybrid platform architecture, implementation of faster build and integration workflows, and rollout of hermetic deployment patterns.
The benefit is not a generic infrastructure modernization project. The benefit is a trading-specific operating model that helps engineering teams move faster, support clients more efficiently, and carry less structural overhead. That is particularly valuable for buy-side platforms and vendors that need both production-grade rigor and commercial flexibility.
The strongest infrastructure story is rarely “look how clever the plumbing is.” It is “this is why the platform ships faster, deploys cleaner, and costs less to operate.” A high-leverage engineering fabric does exactly that.